












HtmlCleaner╩Ūę╗éĆ├Ō┘Mķ_į┤Ą─▀mė├ĘČć·ÅVĄ─JavašZčįHtml╬─ÖnĮŌ╬÷Ų„Ż¼╦³─▄ųžą┬š¹└ĒHTML╬─ÖnĄ─├┐éĆį¬╦ž▓ó╔·│╔ĮYśŗ┴╝║├(Well-Formed)Ą─ HTML ╬─ÖnĪŻ─¼šJ╦³ū±čŁĄ─ęÄät╩ŪŅÉ╦Ųė┌┤¾▓┐Ę▌web×gė[Ų„×ķäō╬─Önī”Ž¾─Żą═╦∙╩╣ė├Ą─ęÄätŻ¼æ¶┐╔ęį╠ß╣®ūįČ©┴xtag║═ęÄätĮMüĒ▀Mąą▀^×V║═Ųź┼õĪŻ
HtmlCleaner▄ø╝■╠ž╔½
╦³▒╗įOėŗĄ─ąĪŻ¼┐ņ╦┘Ż¼ņ`╗ŅČ°Ūę¬Ü┴óĪŻHtmlCleanerę▓┐╔ė├į┌Java┤·┤aųąŻ¼«ö├³┴Ņąą╣żŠ▀╗“Ant╚╬äšĪŻ ĮŌ╬÷║¾ŠÄ│╠▌p┴┐╝ē╬─Önī”Ž¾Ż¼─▄ē“║▄╚▌ęūĄ─▒╗▐DōQĄĮDOM╗“š▀JDomś╦£╩╬─ÖnŻ¼╗“š▀═©▀^Ė„ĘNĘĮ╩Į(ē║┐sŻ¼┤“ėĪ)▀B└m▌ö│÷XMLĪŻ
HtmlCleaner╩╣ė├╩Š└²
īæę╗éĆ£yįćė├Ą─html╬─╝■Ż║html-clean-demo.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd " >
< html xmlns = "http://www.w3.org/1999/xhtml " xml:lang = "zh-CN" dir = "ltr" >
< head >
< meta http-equiv = "Content-Type" content = "text/html; charset=GBK" />
< meta http-equiv = "Content-Language" content = "zh-CN" />
< title > html clean demo </ title >
</ head >
< body >
< div class = "d_1" >
< ul >
< li > bar </ li >
< li > foo </ li >
< li > gzz </ li >
</ ul >
</ div >
< div >
< ul >
< li > < a name = "my_href" href = "1.html" > text-1 </ a > </ li >
< li > < a name = "my_href" href = "2.html" > text-2 </ a > </ li >
< li > < a name = "my_href" href = "3.html" > text-3 </ a > </ li >
< li > < a name = "my_href" href = "4.html" > text-4 </ a > </ li >
</ ul >
</ div >
</ body >
</ html >
Html┤·┤a
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="zh-CN" dir="ltr">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK"/>
<meta http-equiv="Content-Language" content="zh-CN"/>
<title>html clean demo</title>
</head>
<body>
<div class="d_1">
<ul>
<li>bar</li>
<li>foo</li>
<li>gzz</li>
</ul>
</div>
<div>
<ul>
<li><a name="my_href" href="1.html">text-1</a></li>
<li><a name="my_href" href="2.html">text-2</a></li>
<li><a name="my_href" href="3.html">text-3</a></li>
<li><a name="my_href" href="4.html">text-4</a></li>
</ul>
</div>
</body>
</html>
─ŻöMąĶŪ¾Ż║╚Ī│÷titleŻ¼name="my_href" Ą─µ£ĮėŻ¼divĄ─class="d_1"Ž┬Ą─╦∙ėąliā╚╚▌ĪŻŽ┬├µė├htmlcleanerīæ┤·┤aŻ¼HtmlCleanerDemo.java
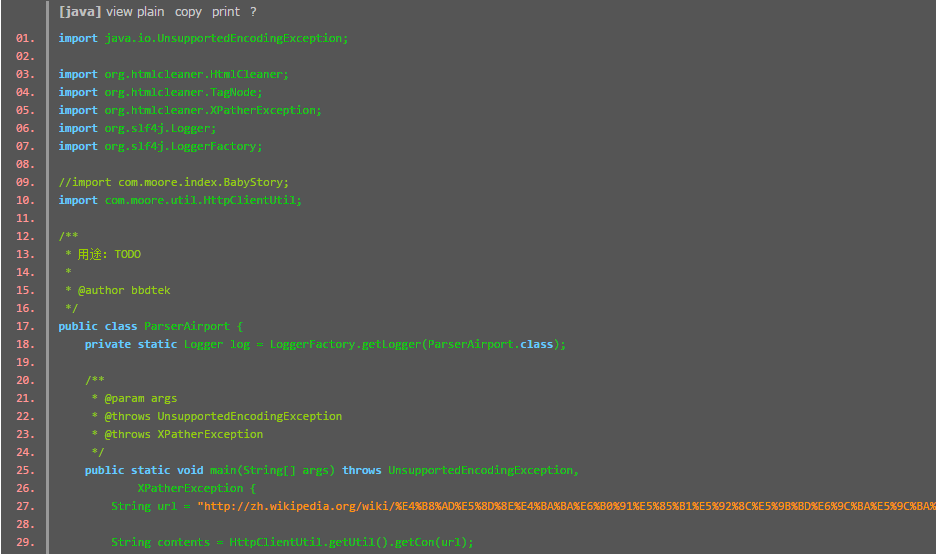
package com.chenlb;
import java.io.File;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.TagNode;
/**
* htmlcleaner ╩╣ė├╩Š└².
*
* @author chenlb 2008-11-26 Ž┬╬ń02:12:02
*/
public class HtmlCleanerDemo {
public static void main(String[] args) throws Exception {
HtmlCleaner cleaner = new HtmlCleaner();
TagNode node = cleaner.clean(new File( "html/html-clean-demo.html" ), "GBK" );
//░┤tag╚Ī.
Object[] ns = node.getElementsByName("title" , true ); //ś╦Ņ}
if (ns.length > 0 ) {
System.out.println("title=" +((TagNode)ns[ 0 ]).getText());
}
System.out.println("ul/li:" );
//░┤xpath╚Ī
ns = node.evaluateXPath("//div[@class='d_1']//li" );
for (Object on : ns) {
TagNode n = (TagNode) on;
System.out.println("\ttext=" +n.getText());
}
System.out.println("a:" );
//░┤ī┘ąįųĄ╚Ī
ns = node.getElementsByAttValue("name" , "my_href" , true , true );
for (Object on : ns) {
TagNode n = (TagNode) on;
System.out.println("\thref=" +n.getAttributeByName( "href" )+ ", text=" +n.getText());
}
}
}
Java┤·┤a
package com.chenlb;
import java.io.File;
import org.htmlcleaner.HtmlCleaner;
import org.htmlcleaner.TagNode;
/**
* htmlcleaner ╩╣ė├╩Š└².
*
* @author chenlb 2008-11-26 Ž┬╬ń02:12:02
*/
public class HtmlCleanerDemo {
public static void main(String[] args) throws Exception {
HtmlCleaner cleaner = new HtmlCleaner();
TagNode node = cleaner.clean(new File("html/html-clean-demo.html"), "GBK");
//░┤tag╚Ī.
Object[] ns = node.getElementsByName("title", true); //ś╦Ņ}
if(ns.length > 0) {
System.out.println("title="+((TagNode)ns[0]).getText());
}
System.out.println("ul/li:");
//░┤xpath╚Ī
ns = node.evaluateXPath("//div[@class='d_1']//li");
for(Object on : ns) {
TagNode n = (TagNode) on;
System.out.println("\ttext="+n.getText());
}
System.out.println("a:");
//░┤ī┘ąįųĄ╚Ī
ns = node.getElementsByAttValue("name", "my_href", true, true);
for(Object on : ns) {
TagNode n = (TagNode) on;
System.out.println("\thref="+n.getAttributeByName("href")+", text="+n.getText());
}
}
}
cleaner.clean()ųąĄ─ģóöĄŻ¼┐╔ęį╩Ū╬─╝■Ż¼┐╔ęį╩ŪurlŻ¼┐╔ęį╩ŪūųĘ¹┤«ā╚╚▌ĪŻéĆ╚╦šJ×ķŻ║▒╚▌^│Żė├Ą─æ¬įō╩ŪevaluateXPathĪó getElementsByAttValueĪógetElementsByNameĘĮĘ©┴╦ĪŻ┴Ē═Ōšf├„Ž┬Ż¼htmlcleaner ī”▓╗ęÄĘČĄ─html╝µ╚▌ąį▒╚▌^║├ĪŻ
HtmlCleanerĖ³ą┬ā╚╚▌
1.HtmlCleanerĄ─╬─Önī”Ž¾─Żą═ōĒėą┴╦ę╗ą®║»öĄŻ¼╠Ä└Ē╣سc║═ī┘ąįŻ¼╦∙ęįį┌ą“┴ą╗»ų«Ū░╦č╦„╗“š▀ŠÄ▌ŗ╩ŪĘŪ│Ż╚▌ęūĄ─ĪŻ
2.╠ß╣®╗∙▒ŠHtmlCleaner DOMĄ─XPathų¦│ų
3.╩╣ė├XML┼õų├╬─╝■ūīäōĮ©Č©ųŲtagūāĄ├Ė³╝ė╚▌ęū
4.ą▐Å═ČÓéĆbugęį╝░APIĖ─▀M
- PC╣┘ĘĮ░µ
- ░▓ū┐╣┘ĘĮ╩ųÖC░µ
- IOS╣┘ĘĮ╩ųÖC░µ

 Ž┬▌d
Ž┬▌d  Ž┬▌d
Ž┬▌d  Ž┬▌d
Ž┬▌d  Ž┬▌d
Ž┬▌d  Ž┬▌d
Ž┬▌d  Ž┬▌d
Ž┬▌d  Apifox(Apiš{įć╣▄└Ē╣żŠ▀)2.1.29.1 ŠG╔½░µ
Apifox(Apiš{įć╣▄└Ē╣żŠ▀)2.1.29.1 ŠG╔½░µ
 ąĪק²ö┤·┤a╣▄└Ē╣żŠ▀(TortoiseGit)2.13.0.1 ųą╬─├Ō┘M░µ
ąĪק²ö┤·┤a╣▄└Ē╣żŠ▀(TortoiseGit)2.13.0.1 ųą╬─├Ō┘M░µ
 SoapUIŲŲĮŌ░µ5.7.0 ūŅą┬░µ
SoapUIŲŲĮŌ░µ5.7.0 ūŅą┬░µ
 ąĪŲż├µ░Õ(phpstudy)8.1.1.3 ╣┘ĘĮūŅą┬░µ
ąĪŲż├µ░Õ(phpstudy)8.1.1.3 ╣┘ĘĮūŅą┬░µ
 Ruby3.0(ruby▀\ąąŁhŠ│)3.0.2 ╣┘ĘĮ░µ
Ruby3.0(ruby▀\ąąŁhŠ│)3.0.2 ╣┘ĘĮ░µ
 gccŠÄūgŲ„( MinGW-w64 9.0.0ŠG╔½░µ)├Ō┘MŽ┬▌d
gccŠÄūgŲ„( MinGW-w64 9.0.0ŠG╔½░µ)├Ō┘MŽ┬▌d
 īÜė±ŠÄ▌ŗų·╩ų0.0.05ą┬░µ
īÜė±ŠÄ▌ŗų·╩ų0.0.05ą┬░µ
 ╗╗©ŠÄ│╠▄ø╝■2.7.2 ╣┘ĘĮpc░µ
╗╗©ŠÄ│╠▄ø╝■2.7.2 ╣┘ĘĮpc░µ
 į│ŠÄ│╠╔┘ā║░Ó┐═æ¶Č╦3.1.1 ╣┘ĘĮ░µ
į│ŠÄ│╠╔┘ā║░Ó┐═æ¶Č╦3.1.1 ╣┘ĘĮ░µ
 Restorator 2009ųą╬─░µå╬╬─╝■Øh╗»░µ
Restorator 2009ųą╬─░µå╬╬─╝■Øh╗»░µ
 ╩«┴∙▀MųŲķåūxąĪ╣żŠ▀
╩«┴∙▀MųŲķåūxąĪ╣żŠ▀
 IT┤a▐r╣żŠ▀▄ø╝■1.0 ųą╬─├Ō┘M░µ
IT┤a▐r╣żŠ▀▄ø╝■1.0 ųą╬─├Ō┘M░µ
 python┼└ŽxīŹæ╚ļķTĮ╠│╠pdf├Ō┘M░µ
python┼└ŽxīŹæ╚ļķTĮ╠│╠pdf├Ō┘M░µ
 Postman Canary(ŠWĒōš{įć▄ø╝■)╣┘ĘĮ░µ7.32.0ŠG╔½├Ō┘M░µ
Postman Canary(ŠWĒōš{įć▄ø╝■)╣┘ĘĮ░µ7.32.0ŠG╔½├Ō┘M░µ
 ┤¾Č·║’╔┘ā║ŠÄ│╠┐═æ¶Č╦1.1.2 ╣┘ĘĮ├Ō┘M░µ
┤¾Č·║’╔┘ā║ŠÄ│╠┐═æ¶Č╦1.1.2 ╣┘ĘĮ├Ō┘M░µ
 excel┼·┴┐sqlšZŠõ(═©▀^excelśŗĮ©sql╣żŠ▀)1.0 ├Ō┘M░µ
excel┼·┴┐sqlšZŠõ(═©▀^excelśŗĮ©sql╣żŠ▀)1.0 ├Ō┘M░µ
 ▄ø╝■╠Ē╝ėÅŚ┤░║═ŠWųĘ╣żŠ▀1.0 ųą╬─├Ō┘M░µ
▄ø╝■╠Ē╝ėÅŚ┤░║═ŠWųĘ╣żŠ▀1.0 ųą╬─├Ō┘M░µ
 ╠ņ░įŠÄ│╠ų·╩ų2.1 å╬╬─╝■ųą╬─░µ
╠ņ░įŠÄ│╠ų·╩ų2.1 å╬╬─╝■ųą╬─░µ
 ida pro ųą╬─ŲŲĮŌ░µ(Ę┤ŠÄūg╣żŠ▀)7.0 ė└śĘØh╗»░µ64╬╗
ida pro ųą╬─ŲŲĮŌ░µ(Ę┤ŠÄūg╣żŠ▀)7.0 ė└śĘØh╗»░µ64╬╗
 VBA┤·┤aų·╩ų3.3.3.1╣┘ĘĮ░µ
VBA┤·┤aų·╩ų3.3.3.1╣┘ĘĮ░µ
 Node.jsķ_░līŹæĮ╠│╠░┘Č╚įŲ═Ļš¹░µĪŠ36šnĪ┐
Node.jsķ_░līŹæĮ╠│╠░┘Č╚įŲ═Ļš¹░µĪŠ36šnĪ┐
 į│ŠÄ│╠ļŖ─XČ╦3.9.1.347 ╣┘ĘĮPC░µ
į│ŠÄ│╠ļŖ─XČ╦3.9.1.347 ╣┘ĘĮPC░µ
 Ųč╣½ėó Android SDKV4.1.11 ╣┘ĘĮūŅą┬░µ
Ųč╣½ėó Android SDKV4.1.11 ╣┘ĘĮūŅą┬░µ
 Ųč╣½ėóiOS SDK2.8.9.1 ╣┘ĘĮūŅą┬░µ
Ųč╣½ėóiOS SDK2.8.9.1 ╣┘ĘĮūŅą┬░µ
 WxPythonųą╬─┐╔ęĢ╗»ŠÄ▌ŗŲ„1.2 ║å¾wųą╬─├Ō┘M░µ
WxPythonųą╬─┐╔ęĢ╗»ŠÄ▌ŗŲ„1.2 ║å¾wųą╬─├Ō┘M░µ
 Python┤·┤a╔·│╔Ų„1.0 ųą╬─├Ō┘M░µ
Python┤·┤a╔·│╔Ų„1.0 ųą╬─├Ō┘M░µ
 CšZčį┤·┤aīŹ└²ų·╩ų1.0 ├Ō┘M░µ
CšZčį┤·┤aīŹ└²ų·╩ų1.0 ├Ō┘M░µ
 c primer plusĄ┌6░µųą╬─░µĖ▀ŪÕ░µ
c primer plusĄ┌6░µųą╬─░µĖ▀ŪÕ░µ
 C++ Primer Plus 2021ļŖūė░µūŅą┬░µ
C++ Primer Plus 2021ļŖūė░µūŅą┬░µ
 notepad++7.8.2 ųą╬─├Ō┘M░µ
notepad++7.8.2 ųą╬─├Ō┘M░µ




 Microsoft Spy++9.10 ųą╬─ŠG╔½░µ
Microsoft Spy++9.10 ųą╬─ŠG╔½░µ į┤┤·┤a▒Żūo╣żŠ▀(Dotfuscator Professional
į┤┤·┤a▒Żūo╣żŠ▀(Dotfuscator Professional  MDBöĄō■Äņ╣▄└Ē▄ø╝■1.0 ųą╬─├Ō┘M░µ
MDBöĄō■Äņ╣▄└Ē▄ø╝■1.0 ųą╬─├Ō┘M░µ į┤┤a░▓╚½▒O£y╣żŠ▀(Fortify SCA 2016)ĪŠĖĮcr
į┤┤a░▓╚½▒O£y╣żŠ▀(Fortify SCA 2016)ĪŠĖĮcr RTX ServerSDK 2015╣┘ĘĮūŅą┬░µ
RTX ServerSDK 2015╣┘ĘĮūŅą┬░µ ░óžł┤«┐┌š{įćų·╩ų2.4.0.0ŠG╔½├Ō┘M░µ
░óžł┤«┐┌š{įćų·╩ų2.4.0.0ŠG╔½├Ō┘M░µ Š½ęūšōē»SQLšZŠõ╔·│╔Ų„2.1 ŠG╔½ūŅą┬░µ ĪŠ
Š½ęūšōē»SQLšZŠõ╔·│╔Ų„2.1 ŠG╔½ūŅą┬░µ ĪŠ javaķ_į┤ł¾▒ĒŽĄĮy(JasperReports Library)6
javaķ_į┤ł¾▒ĒŽĄĮy(JasperReports Library)6 ¬Ü┴ółFė╬æ“ū„Ę╗┤░┐┌Ęų╬÷╣żŠ▀ĪŠVIP╚½╠ūĮ╠│╠╝░
¬Ü┴ółFė╬æ“ū„Ę╗┤░┐┌Ęų╬÷╣żŠ▀ĪŠVIP╚½╠ūĮ╠│╠╝░